人工智能¶
Note
该组件旨在为边缘设备提供轻量级的神经网络推理与训练能力,主打 on-device learning。整个库以 C++17 编写,保持极小的依赖面,专门针对 ESP32-S3 (WROOM-1U) 等具备 PSRAM 的微控制器优化。
Note
tiny_ai 处于 TinyAuton 中间件依赖链 tiny_toolbox → tiny_math → tiny_dsp → tiny_ai 的最上层,复用 tiny_math 提供的张量/矩阵原语和 tiny_dsp 提供的频域 / 滤波 / 重采样能力,从信号采集到模型推理形成完整的端侧链路。
组件依赖¶
# tiny_ai component CMakeLists.txt
set(src_dirs
.
core
layers
models
quant
train
example
)
set(include_dirs
.
include
core
layers
models
quant
train
example/data
)
set(requires
tiny_dsp
)
idf_component_register(
SRC_DIRS ${src_dirs}
INCLUDE_DIRS ${include_dirs}
REQUIRES ${requires}
)
架构与功能目录¶
依赖关系示意图¶
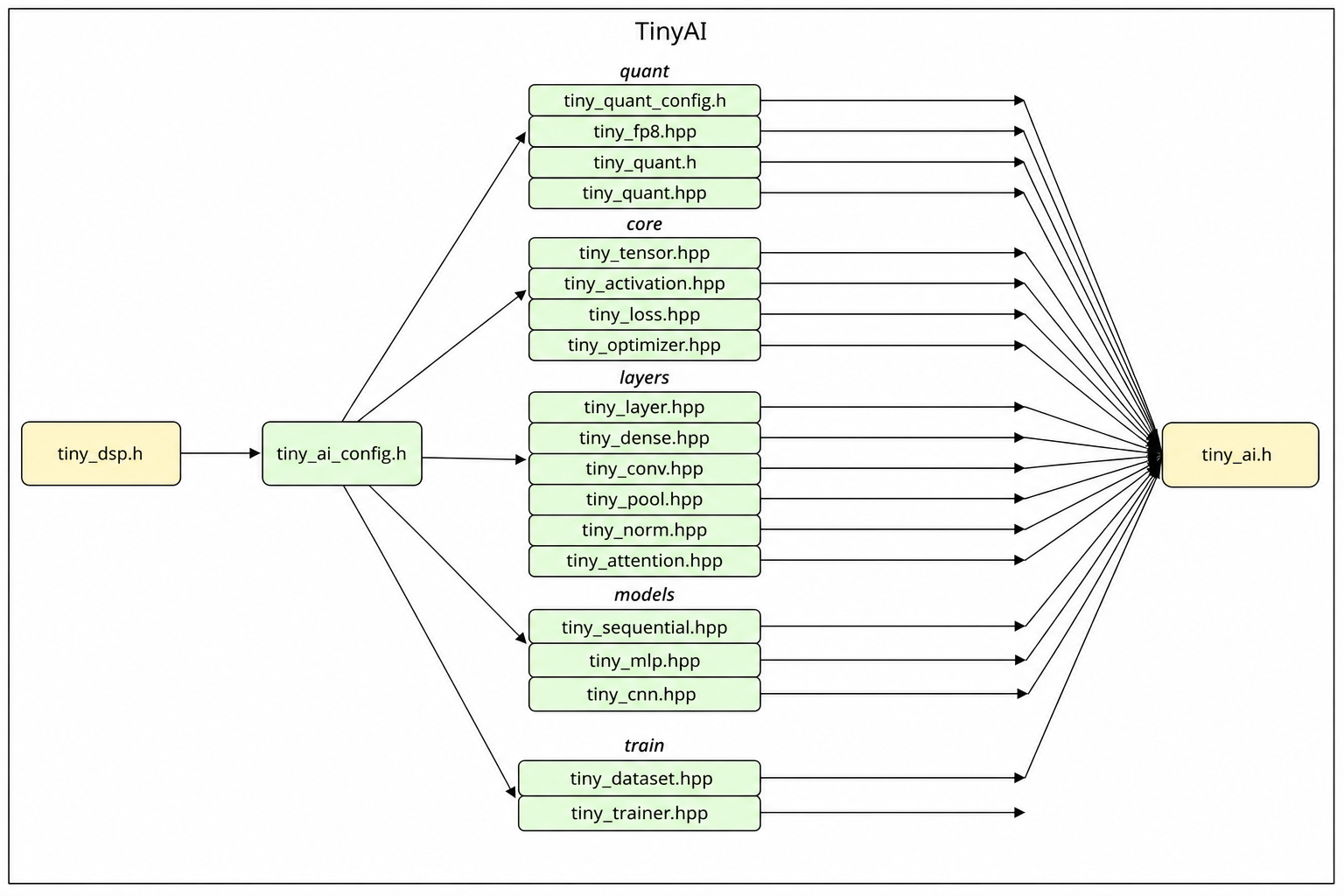
代码树¶
tiny_ai/
├── include/
│ ├── tiny_ai.h # 统一入口头文件
│ └── tiny_ai_config.h # 平台 / PSRAM / 训练开关 / 错误码
│
├── core/ # 张量与训练原语
│ ├── tiny_tensor.{hpp,cpp} # N 维 (≤4D) float32 张量
│ ├── tiny_activation.{hpp,cpp} # ReLU / LeakyReLU / Sigmoid / Tanh / Softmax / GELU / Linear
│ ├── tiny_loss.{hpp,cpp} # MSE / MAE / CrossEntropy / BinaryCE
│ └── tiny_optimizer.{hpp,cpp} # SGD (动量 + L2)、Adam
│
├── layers/ # 神经网络层
│ ├── tiny_layer.{hpp,cpp} # Layer 抽象 + ActivationLayer / Flatten / GlobalAvgPool
│ ├── tiny_dense.{hpp,cpp} # 全连接层 (Xavier 初始化)
│ ├── tiny_conv.{hpp,cpp} # Conv1D / Conv2D (He 初始化)
│ ├── tiny_pool.{hpp,cpp} # MaxPool / AvgPool 1D & 2D
│ ├── tiny_norm.{hpp,cpp} # LayerNorm
│ └── tiny_attention.{hpp,cpp} # Multi-Head Self-Attention
│
├── models/ # 高层模型容器
│ ├── tiny_sequential.{hpp,cpp} # Sequential 层堆叠器
│ ├── tiny_mlp.{hpp,cpp} # MLP 便捷封装
│ └── tiny_cnn.{hpp,cpp} # CNN1D 便捷封装 (CNN1DConfig)
│
├── quant/ # 量化子系统
│ ├── tiny_quant_config.h # tiny_dtype_t / tiny_quant_params_t
│ ├── tiny_quant.{h,c} # C 接口:INT8 / INT16 量化 + INT8 dense forward
│ ├── tiny_quant.{hpp,cpp} # C++ Tensor 级 PTQ 工具
│ └── tiny_fp8.{hpp,cpp} # FP8 E4M3FN / E5M2 软件实现
│
├── train/ # 训练循环
│ ├── tiny_dataset.{hpp,cpp} # Dataset:shuffle / split / next_batch
│ └── tiny_trainer.{hpp,cpp} # Trainer:fit / evaluate
│
└── example/ # 端到端示例
├── data/iris_data.hpp # Iris 分类数据集(150 × 4 → 3 类)
├── data/signal_data.hpp # 合成 1-D 信号(3 类,64 点/样本)
├── example_mlp.cpp # MLP + INT8 PTQ 演示
├── example_cnn.cpp # CNN1D + FP8 压缩演示
└── example_attention.cpp # 小型 Transformer (Iris)
特性矩阵¶
| 特性 | 配置宏 / 接口 | 说明 |
|---|---|---|
| 训练开关 | TINY_AI_TRAINING_ENABLED | 设为 0 编译纯推理,移除全部反向通路与梯度缓冲 |
| PSRAM 分配 | TINY_AI_USE_PSRAM、TINY_AI_MALLOC_PSRAM | 大张量(权重 / 激活)走 8 MB PSRAM,小张量走内部 SRAM |
| INT8 量化 | TINY_AI_QUANT_INT8 | 对称量化、min-max 校准、INT32 累加 dense forward |
| INT16 量化 | TINY_AI_QUANT_INT16 | 对称量化,更高精度备份 |
| FP8 量化 | TINY_AI_QUANT_FP8 | 软件实现 OCP 规范的 E4M3FN(权重/激活)与 E5M2(梯度) |
设计要点¶
- C++17 + 命名空间
tiny:所有 C++ 类与函数都在namespace tiny内;C 接口(tiny_quant.h、错误码)保留于全局空间。 - 形状约定:
Tensor最多 4D;常见排布为[batch, ...]行主序,Conv1D 输入[B, C, L]、Conv2D 输入[B, C, H, W]、Attention 输入[B, S, E]。 - 反向缓存:训练开启时,每个层在
forward()内把必要的输入或输出缓存到内部成员(如x_cache_、A_cache_),backward()直接复用,避免重复计算。 - 参数收集:
Sequential::collect_params()递归调用每层的collect_params(),把(param, grad)对压入std::vector<ParamGroup>,Optimizer::init()据此分配动量 / Adam 一阶二阶矩缓冲。 - 量化路径:建议训练后采用 PTQ:
calibrate(weight, dtype)→quantize(weight, buf, qp)→ 在 INT8 dense kernel 上推理。