说明¶
1. 算法原理¶
卷积是信号处理中的基础运算,将两个信号合并生成第三个信号。数学定义如下:
其中 \(x(t)\) 是输入信号,\(h(t)\) 是卷积核(脉冲响应),\(y(t)\) 是输出。离散域中:
卷积核 \(h\) 被 翻转 (时间反转)后 滑过 信号 \(x\)。在每个移位位置,重叠值相乘并求和。
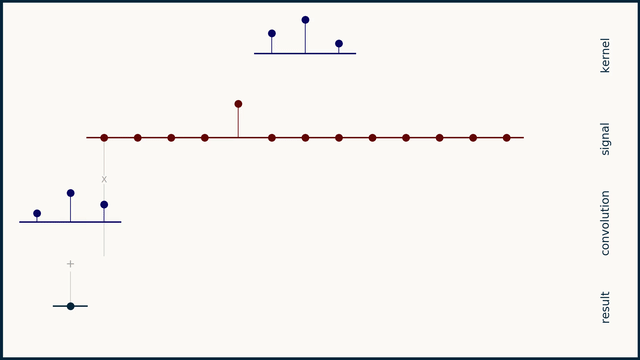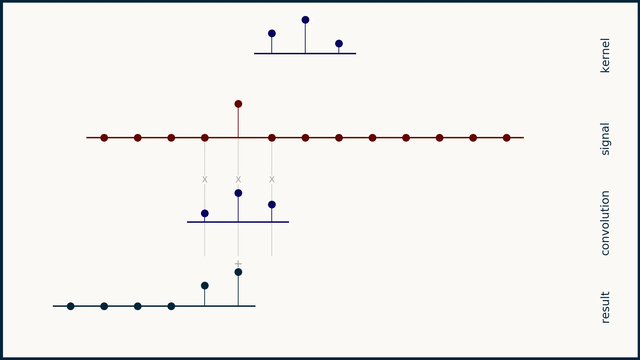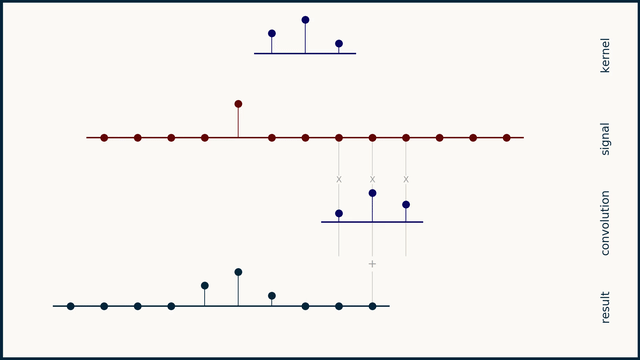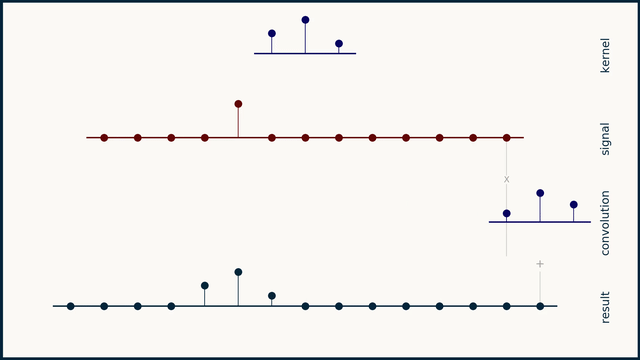
-
卷积的物理意义
1.1 完整卷积(默认输出)¶
长度为 \(L_s\) 的信号与长度为 \(L_k\) 的卷积核的完整卷积产生 \(L_s + L_k - 1\) 个输出点。计算自然地分三个阶段进行:
- 阶段 I (上升期):卷积核仅部分覆盖信号左边缘
- 阶段 II (稳态期):卷积核完全在信号内部
- 阶段 III (下降期):卷积核滑过右边缘
1.2 填充模式¶
当卷积核超出信号边界时,由填充提供合成样本:
| 模式 | 行为 |
|---|---|
零填充 (TINY_PADDING_ZERO) | 缺失样本视为 0.0 |
对称填充 (TINY_PADDING_SYMMETRIC) | 在边缘处镜像信号 |
周期填充 (TINY_PADDING_PERIODIC) | 信号环绕(循环) |
1.3 输出模式¶
| 模式 | 输出长度 | 说明 |
|---|---|---|
完整 (TINY_CONV_FULL) | siglen + kernlen - 1 | 完整卷积结果 |
头部 (TINY_CONV_HEAD) | kernlen | 前 kernlen 个点 |
中心 (TINY_CONV_CENTER) | siglen | 居中部分,与信号长度一致 |
尾部 (TINY_CONV_TAIL) | kernlen | 后 kernlen 个点 |
2. 代码设计理念¶
2.1 双路径架构(ESP32 vs 通用)¶
这是全库中 唯一 使用平台特定加速的卷积模块。在 ESP32 上,使用 ESP- DSP 库的 dsps_conv_f32 进行硬件优化卷积。通用回退路径使用纯 C 三阶段实现,可处理任意信号/卷积核长度顺序 。
2.2 三段式通用卷积¶
通用卷积显式组织为三个循环(阶段 I/II/III)。这种形式:
- 比带 min/max 钳制的单循环更清晰可读
- 允许编译器对每个阶段独立优化
- 正确处理
siglen >= kernlen和siglen < kernlen两种情况
平台不对称重要提示:ESP32 ESP-DSP 后端 要求 siglen >= kernlen,如果违反此条件返回 TINY_ERR_DSP_INVALID_PARAM。通用回退路径没有此限制。
2.3 const 正确性¶
信号和卷积核指针在通用路径中均视为只读(const float *),防止意外修改,并允许编译器进行更优的别名分析。
2.4 memmove 结果切片¶
tiny_conv_ex_f32 通过将数据前移到输出缓冲区开头来选取完整卷积的子切片。使用 memmove 而非 for 循环或 memcpy,因为源和目标区域可能重叠(例如 Center 模式中 start_idx > 0 时)。
2.5 扩展模式的动态分配¶
tiny_conv_ex_f32 通过 calloc 分配填充临时缓冲区。这是由于填充增加了 2 * (kernlen - 1) 个额外采样点。缓冲区在返回前释放。对于实时或内存受限的应用,应使用不进行动态分配的 tiny_conv_f32。
3. API 接口 — 函数¶
3.1 tiny_conv_f32¶
/**
* @name: tiny_conv_f32
* @brief Convolution function (full mode, zero padding implicit)
*
* @param Signal The input signal array
* @param siglen The length of the input signal array (> 0)
* @param Kernel The input kernel array
* @param kernlen The length of the input kernel array (> 0)
* @param convout The output array for the convolution result.
* Caller MUST provide at least (siglen + kernlen - 1) elements.
*
* @note On ESP32 the underlying ESP-DSP routine additionally requires
* siglen >= kernlen; the generic fallback handles both orderings.
*
* @return tiny_error_t
*/
tiny_error_t tiny_conv_f32(const float *Signal, const int siglen,
const float *Kernel, const int kernlen,
float *convout)
{
if (NULL == Signal || NULL == Kernel || NULL == convout)
return TINY_ERR_DSP_NULL_POINTER;
if (siglen <= 0 || kernlen <= 0)
return TINY_ERR_DSP_INVALID_PARAM;
#if MCU_PLATFORM_SELECTED == MCU_PLATFORM_ESP32
/* ESP-DSP 要求 siglen >= kernlen */
if (siglen < kernlen)
return TINY_ERR_DSP_INVALID_PARAM;
dsps_conv_f32(Signal, siglen, Kernel, kernlen, convout);
#else
const float *sig = Signal;
const float *kern = Kernel;
int lsig = siglen;
int lkern = kernlen;
// 阶段 I — 上升期(卷积核部分覆盖左边缘)
for (int n = 0; n < lkern; n++)
{
convout[n] = 0;
for (int k = 0; k <= n; k++)
convout[n] += sig[k] * kern[n - k];
}
// 阶段 II — 稳态期(卷积核完全在信号内部)
for (int n = lkern; n < lsig; n++)
{
convout[n] = 0;
int kmin = n - lkern + 1;
int kmax = n;
for (int k = kmin; k <= kmax; k++)
convout[n] += sig[k] * kern[n - k];
}
// 阶段 III — 下降期(卷积核滑过右边缘)
for (int n = lsig; n < lsig + lkern - 1; n++)
{
convout[n] = 0;
int kmin = n - lkern + 1;
int kmax = lsig - 1;
for (int k = kmin; k <= kmax; k++)
convout[n] += sig[k] * kern[n - k];
}
#endif
return TINY_OK;
}
描述:
计算输入信号与卷积核的完整卷积。在 ESP32 上,委托硬件加速的 dsps_conv_f32。在所有其他平台,使用三阶段纯 C 实现。
特点:
- 零拷贝:无动态内存分配
- ESP32 平台加速
- 通用回退路径支持任意信号/卷积核长度顺序
参数:
| 参数 | 类型 | 说明 |
|---|---|---|
Signal | const float* | 输入信号数组指针 |
siglen | int | 输入信号长度(> 0) |
Kernel | const float* | 卷积核数组指针 |
kernlen | int | 卷积核长度(> 0) |
convout | float* | 卷积结果输出缓冲区。必须至少容纳 siglen + kernlen - 1 个元素 |
返回值:
| 码值 | 含义 |
|---|---|
TINY_OK | 卷积成功 |
TINY_ERR_DSP_NULL_POINTER | Signal、Kernel 或 convout 为空 |
TINY_ERR_DSP_INVALID_PARAM | siglen ≤ 0、kernlen ≤ 0,或(仅 ESP32)siglen < kernlen |
3.2 tiny_conv_ex_f32¶
/**
* @name: tiny_conv_ex_f32
* @brief Extended convolution function with padding and mode options
*
* @param Signal The input signal array
* @param siglen The length of the input signal array (> 0)
* @param Kernel The input kernel array
* @param kernlen The length of the input kernel array (> 0)
* @param convout The output buffer for the convolution result.
* Must hold at least (siglen + kernlen - 1) elements
* @param padding_mode Padding mode (zero, symmetric, periodic)
* @param conv_mode Convolution mode (full, head, center, tail)
*
* @return tiny_error_t
*/
tiny_error_t tiny_conv_ex_f32(const float *Signal, const int siglen,
const float *Kernel, const int kernlen,
float *convout,
tiny_padding_mode_t padding_mode,
tiny_conv_mode_t conv_mode)
{
if (NULL == Signal || NULL == Kernel || NULL == convout)
return TINY_ERR_DSP_NULL_POINTER;
if (siglen <= 0 || kernlen <= 0)
return TINY_ERR_DSP_INVALID_PARAM;
#if MCU_PLATFORM_SELECTED == MCU_PLATFORM_ESP32
/* 快速路径:仅当三个条件全部满足时委托硬件 */
if (padding_mode == TINY_PADDING_ZERO &&
conv_mode == TINY_CONV_FULL &&
siglen >= kernlen)
{
dsps_conv_f32(Signal, siglen, Kernel, kernlen, convout);
return TINY_OK;
}
#endif
int pad_len = kernlen - 1;
int padded_len = siglen + 2 * pad_len;
float *padded_signal = (float *)calloc(padded_len, sizeof(float));
if (padded_signal == NULL)
return TINY_ERR_DSP_MEMORY_ALLOC;
switch (padding_mode)
{
case TINY_PADDING_ZERO:
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen);
break;
case TINY_PADDING_SYMMETRIC:
for (int i = 0; i < pad_len; i++)
{
padded_signal[pad_len - 1 - i] = Signal[i];
padded_signal[pad_len + siglen + i] = Signal[siglen - 1 - i];
}
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen);
break;
case TINY_PADDING_PERIODIC:
for (int i = 0; i < pad_len; i++)
{
padded_signal[pad_len - 1 - i] = Signal[(siglen - pad_len + i) % siglen];
padded_signal[pad_len + siglen + i] = Signal[i % siglen];
}
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen);
break;
default:
free(padded_signal);
return TINY_ERR_DSP_INVALID_PARAM;
}
// 在填充信号上计算完整卷积
int convlen_full = siglen + kernlen - 1;
for (int n = 0; n < convlen_full; n++)
{
float sum = 0.0f;
for (int k = 0; k < kernlen; k++)
sum += padded_signal[n + k] * Kernel[kernlen - 1 - k];
convout[n] = sum;
}
free(padded_signal);
if (conv_mode == TINY_CONV_FULL)
return TINY_OK;
int start_idx = 0;
int out_len = 0;
switch (conv_mode)
{
case TINY_CONV_HEAD: start_idx = 0; out_len = kernlen; break;
case TINY_CONV_CENTER: start_idx = (kernlen-1)/2; out_len = siglen; break;
case TINY_CONV_TAIL: start_idx = siglen - 1; out_len = kernlen; break;
default: return TINY_ERR_DSP_INVALID_MODE;
}
/* memmove:源和目标可能重叠 */
if (start_idx > 0 && out_len > 0)
memmove(convout, convout + start_idx, sizeof(float) * (size_t)out_len);
return TINY_OK;
}
描述:
通过显式控制填充策略和输出切片选择进行卷积计算。始终先在信号填充版本上计算完整卷积,然后通过原地 memmove 提取请求的输出模式。
特点:
- 三种填充模式:零、对称、周期
- 四种输出模式:完整、头部、中心、尾部
- ESP32 快速路径:仅当三个条件全部满足时启用(零 + 完整 + siglen >= kernlen)
- 使用
memmove安全进行重叠切片提取
参数:
| 参数 | 类型 | 说明 |
|---|---|---|
Signal | const float* | 输入信号数组指针 |
siglen | int | 输入信号长度(> 0) |
Kernel | const float* | 卷积核数组指针 |
kernlen | int | 卷积核长度(> 0) |
convout | float* | 输出缓冲区。无论 conv_mode 如何,必须至少容纳 siglen + kernlen - 1 个元素 |
padding_mode | tiny_padding_mode_t | 填充策略:TINY_PADDING_ZERO、TINY_PADDING_SYMMETRIC 或 TINY_PADDING_PERIODIC |
conv_mode | tiny_conv_mode_t | 输出切片:TINY_CONV_FULL、TINY_CONV_HEAD、TINY_CONV_CENTER 或 TINY_CONV_TAIL |
返回值:
| 码值 | 含义 |
|---|---|
TINY_OK | 卷积成功 |
TINY_ERR_DSP_NULL_POINTER | Signal、Kernel 或 convout 为空 |
TINY_ERR_DSP_INVALID_PARAM | siglen ≤ 0 或 kernlen ≤ 0 |
TINY_ERR_DSP_MEMORY_ALLOC | 填充信号的 calloc 失败 |
TINY_ERR_DSP_INVALID_MODE | 未知的 conv_mode 值 |
4. 函数对比¶
| 特性 | tiny_conv_f32 | tiny_conv_ex_f32 |
|---|---|---|
| 填充模式 | 仅零填充(隐式) | 零、对称或周期(显式) |
| 输出模式 | 仅完整卷积 | 完整、头部、中心或尾部 |
| 输出长度 | siglen + kernlen - 1 | 根据 conv_mode 可配置 |
| 内存分配 | 无(零拷贝) | calloc 填充缓冲区(2 × pad_len + siglen 个浮点) |
| ESP32 快速路径 | 总是(若 siglen >= kernlen) | 仅零 + 完整 + siglen >= kernlen |
| 信号/核顺序 | 通用路径:任意;ESP32:siglen >= kernlen | 通用路径:任意;ESP32快速路径:siglen >= kernlen |
| 边界处理 | 三阶段循环隐式零填充 | 显式填充(零/对称/周期) |
| 适用场景 | 简单完整卷积、实时、无内存分配 | 需要自定义填充或输出切片 |
何时使用 tiny_conv_f32¶
- 需要简单的完整卷积结果
- 边界处零填充可接受
- 追求最优性能(ESP32 硬件加速)
- 需要完全避免动态内存分配
- 实时或中断上下文处理
何时使用 tiny_conv_ex_f32¶
- 需要对称或周期填充以减少边界伪影
- 需要提取结果的特定部分(头部/中心/尾部)
- 需要输出长度等于输入信号长度(中心模式),省去手动切片
- 信号边界处理至关重要(图像滤波、循环卷积、周期信号)
- 可容忍每次调用一次性
calloc/free
5. ⚠️ 重要注意事项¶
5.1 输出缓冲区最小大小¶
无论 conv_mode 如何,两个函数的输出缓冲区都必须按 完整卷积 大小分配:
在 tiny_conv_ex_f32 中,完整结果先写入,然后将请求的切片前移。如果缓冲区小于 siglen + kernlen - 1,将导致堆缓冲区溢出。
5.2 ESP32 信号/卷积核长度顺序¶
在 ESP32 上,dsps_conv_f32 要求 siglen >= kernlen。如果违反此条件:
tiny_conv_f32返回TINY_ERR_DSP_INVALID_PARAMtiny_conv_ex_f32回退到通用路径(可处理任意顺序)
建议:便携代码始终确保 siglen >= kernlen。
5.3 扩展模式的动态分配¶
tiny_conv_ex_f32 内部调用 calloc。如果分配失败: - 返回 TINY_ERR_DSP_MEMORY_ALLOC - 输出缓冲区不会被修改
在内存受限或实时系统中,应优先使用 tiny_conv_f32 或外部预分配填充缓冲区。
5.4 memmove vs memcpy¶
tiny_conv_ex_f32 使用 memmove(非 memcpy)进行切片提取,因为源和目标范围可能重叠。例如 Center 模式中,convout[start_idx] 的字节复制到 convout[0],当 start_idx < out_len 时这些区域存在重叠。
5.5 填充模式与信号长度¶
- 对称和周期填充都会读取
Signal[0]和Signal[siglen-1]用于镜像/环绕操作。若siglen == 1,左右填充边缘引用同一样本。 - 周期模式使用
% siglen—— 若siglen == 0会导致除零错误,但这已被siglen <= 0参数检查截获。
5.6 卷积 ≠ 相关¶
卷积翻转核,相关不翻转。若需相关运算,请使用 CORRELATION 模块的 tiny_corr_f32 或 tiny_ccorr_f32——不要手动反转卷积核,因为内部边界处理存在差异。