说明¶
说明
Trainer 把 Sequential 模型、Optimizer、损失函数、Dataset 串成一条标准训练流水线,提供 fit / evaluate_loss / evaluate_accuracy 三个 API。它在第一次调用时自动收集模型参数并初始化优化器,因此应用层只需要描述「网络 + 优化器 + 损失」即可开始训练。
Trainer — 训练循环:重复 forward → loss → backward → 更新
Trainer 封装了一个最经典的训练循环。你不需要自己写循环。
算法直觉¶
一个 Epoch 内发生了什么¶
for each batch:
1. forward: model(batch) → 预测输出
2. loss: loss_fn(预测, 真实标签) → 损失值
3. backward: 损失梯度反向传播 → 每个参数得到梯度
4. step: optimizer 用梯度更新所有参数
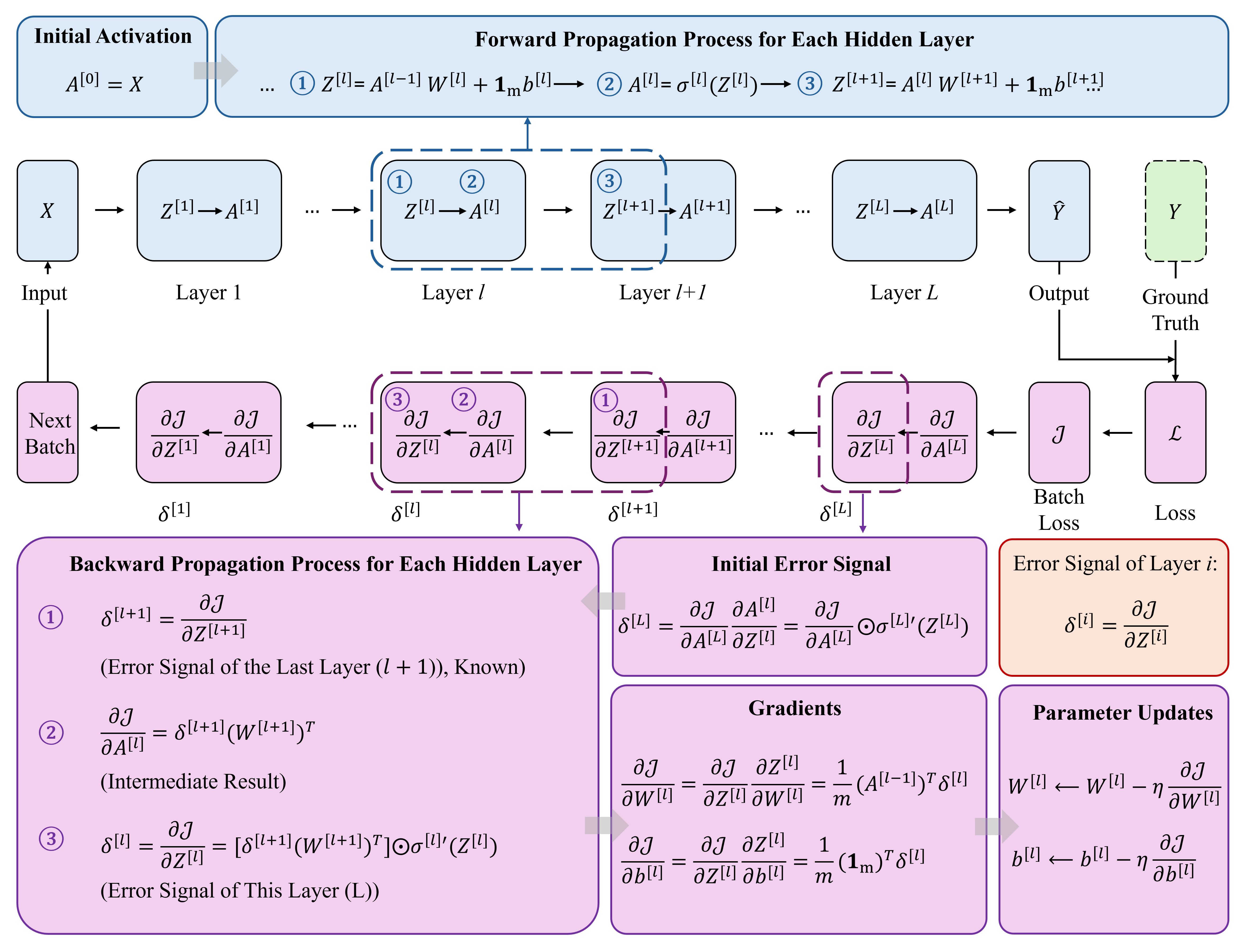
核心流程¶
Trainer trainer(&model, &optimizer); // 绑定模型和优化器
trainer.fit(&dataset, 100, 16); // 100 epochs, batch size = 16
- epoch = 完整过一遍训练集
- batch size = 每次同时算几个样本
- fit 过程:每个 epoch 后输出平均损失和准确率(如果有验证集)
监控训练¶
fit() 内部调用 evaluate_loss() 和 evaluate_accuracy() 在 epoch 结束时输出指标。你应该关注:
- 损失是否持续下降? → 正常
- 损失震荡不降? → 学习率太大或 batch size 太小
- 训练准确率高但验证准确率低? → 过拟合,加 weight_decay 或减小网络
类定义¶
class Trainer
{
public:
struct Config
{
int epochs = 100;
int batch_size = 16;
bool verbose = true;
int print_every = 10;
};
Trainer(Sequential *model, Optimizer *optimizer,
LossType loss_type = LossType::CROSS_ENTROPY);
void fit(Dataset &train_data, const Config &cfg = Config{},
Dataset *val_data = nullptr);
float evaluate_loss (Dataset &data, int batch_size = 16);
float evaluate_accuracy(Dataset &data, int batch_size = 16);
private:
void ensure_params_collected();
Sequential *model_;
Optimizer *optimizer_;
LossType loss_type_;
std::vector<ParamGroup> params_;
bool params_collected_;
};
Trainer 仅持有指针:模型与优化器的生命周期由调用方管理。
fit 流程¶
void Trainer::fit(Dataset &train_data, const Config &cfg, Dataset *val_data)
{
ensure_params_collected(); // 第一次调用时初始化优化器
int *y_batch = TINY_AI_MALLOC(...);
for (int epoch = 0; epoch < cfg.epochs; epoch++)
{
train_data.shuffle(epoch + 1);
...
while (next_batch returns > 0)
{
Tensor logits = model_->forward(X_batch);
float loss = loss_forward(logits, ..., loss_type_, y_batch);
optimizer_->zero_grad(params_);
Tensor grad = loss_backward(logits, ..., loss_type_, y_batch);
model_->backward(grad);
optimizer_->step(params_);
}
if (val_data) print "Epoch loss= val_acc="
else print "Epoch loss="
}
}
要点:
- 每个 epoch 自动
train_data.shuffle(epoch + 1),避免常见的「同顺序训练偏差」。 - 损失函数同时支持
MSE / MAE / CROSS_ENTROPY / BINARY_CE:对分类任务,Tensor target = zeros_like(logits)仅占位,真正的标签从y_batch读取。 cfg.print_every控制日志频率:每print_every个 epoch 打印一次损失(如有val_data,附带验证准确率)。
evaluateloss / evaluateaccuracy¶
float evaluate_loss(Dataset &data, int batch_size = 16);
float evaluate_accuracy(Dataset &data, int batch_size = 16);
- 内部都
data.reset()后逐批执行forward,不会修改模型参数。 evaluate_loss返回各 batch 平均损失。evaluate_accuracy用Sequential::predict计算 argmax,再与真实y_batch比较,返回正确率。
使用示例¶
using namespace tiny;
Dataset full(X, y, N, F, C);
Dataset train, test;
full.split(0.2f, train, test, 42);
MLP model({F, 16, 8, C}, ActType::RELU);
Adam opt(1e-3f);
Trainer trainer(&model, &opt, LossType::CROSS_ENTROPY);
Trainer::Config cfg;
cfg.epochs = 100;
cfg.batch_size = 16;
cfg.print_every = 10;
trainer.fit(train, cfg, &test);
printf("Final test acc = %.4f\n", trainer.evaluate_accuracy(test));
训练开关¶
TINY_AI_TRAINING_ENABLED == 0时,整个Trainer类(包括fit / evaluate_*)会被预处理移除,只保留模型推理 API。- 部署到 ESP32-S3 时,可以在
make/idf.py menuconfig阶段单独关闭训练,节省 ROM 与 RAM。
自定义训练循环¶
如果默认 fit 满足不了需求(例如要做学习率调度、混合精度、自定义日志),可以仿照 example_attention.cpp 中那种「手写 forward / backward / step」的模式,仅复用 Dataset 与 Optimizer:
std::vector<ParamGroup> params;
model.collect_params(params);
opt.init(params);
for (...)
{
int actual = ds.next_batch(X_batch, y_batch, batch_size);
Tensor logits = model.forward(X_batch);
Tensor dlog = cross_entropy_backward(logits, y_batch);
opt.zero_grad(params);
model.backward(dlog);
opt.step(params);
}