说明¶
卷积的数学原理¶
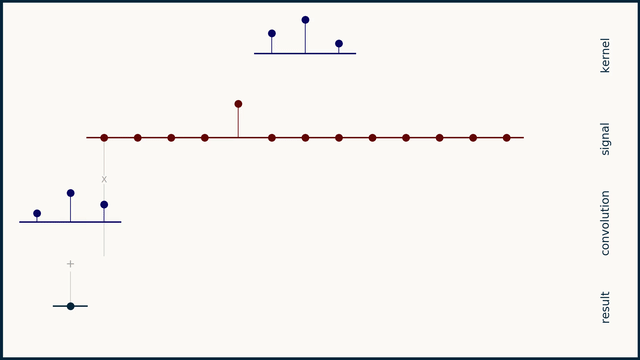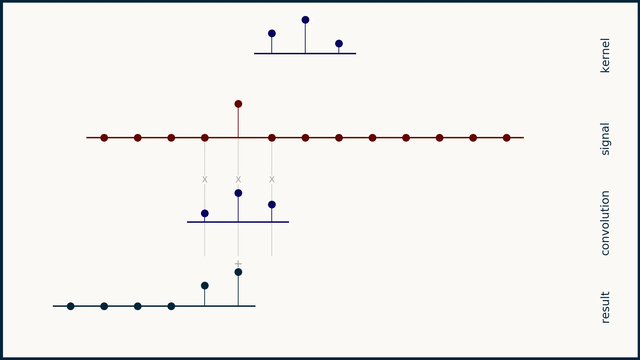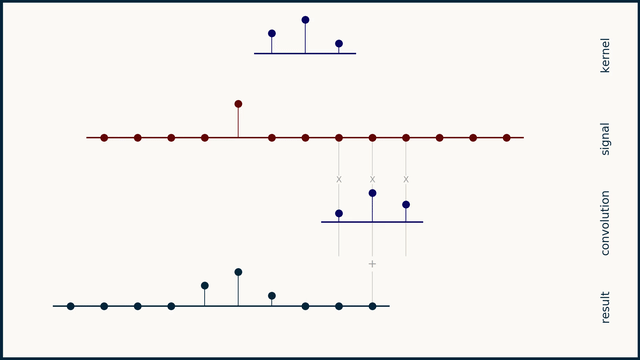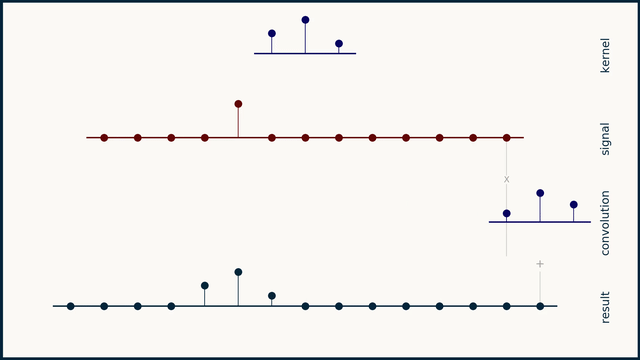
卷积是信号处理中的一种重要操作,用于描述两个信号之间的关系。它可以看作是一个信号与另一个信号的加权平均。卷积的数学定义如下:
其中,\(x(t)\) 是输入信号,\(h(t)\) 是系统的脉冲响应,\(y(t)\) 是输出信号。卷积的结果是一个新的信号,它包含了输入信号和系统脉冲响应之间的所有信息。
-
卷积的物理意义
编程思路¶
本库中的卷积操作实际上是将卷积核调转方向然后与输入信号进行逐点相乘并求和。
tiny_conv_f32¶
/**
* @name: tiny_conv_f32
* @brief Convolution function
*
* @param Signal The input signal array
* @param siglen The length of the input signal array
* @param Kernel The input kernel array
* @param kernlen The length of the input kernel array
* @param convout The output array for the convolution result
*
* @return tiny_error_t
*/
tiny_error_t tiny_conv_f32(const float *Signal, const int siglen, const float *Kernel, const int kernlen, float *convout)
{
if (NULL == Signal || NULL == Kernel || NULL == convout)
{
return TINY_ERR_DSP_NULL_POINTER;
}
if (siglen <= 0 || kernlen <= 0)
{
return TINY_ERR_DSP_INVALID_PARAM;
}
if (siglen < kernlen)
{
return TINY_ERR_DSP_INVALID_PARAM;
}
#if MCU_PLATFORM_SELECTED == MCU_PLATFORM_ESP32
// ESP32 DSP library
dsps_conv_f32(Signal, siglen, Kernel, kernlen, convout);
#else
float *sig = (float *)Signal;
float *kern = (float *)Kernel;
int lsig = siglen;
int lkern = kernlen;
// stage I
for (int n = 0; n < lkern; n++)
{
size_t k;
convout[n] = 0;
for (k = 0; k <= n; k++)
{
convout[n] += sig[k] * kern[n - k];
}
}
// stage II
for (int n = lkern; n < lsig; n++)
{
size_t kmin, kmax, k;
convout[n] = 0;
kmin = n - lkern + 1;
kmax = n;
for (k = kmin; k <= kmax; k++)
{
convout[n] += sig[k] * kern[n - k];
}
}
// stage III
for (int n = lsig; n < lsig + lkern - 1; n++)
{
size_t kmin, kmax, k;
convout[n] = 0;
kmin = n - lkern + 1;
kmax = lsig - 1;
for (k = kmin; k <= kmax; k++)
{
convout[n] += sig[k] * kern[n - k];
}
}
#endif
return TINY_OK;
}
描述:
该函数实现了对输入信号和卷积核的卷积操作。它首先检查输入参数是否为NULL,然后根据平台选择使用ESP32 DSP库或标准C实现进行卷积计算。函数返回卷积结果。
特点:
-
支持ESP32 DSP库加速
-
支持卷积核和信号互换以保证信号长度大于卷积核长度
参数:
-
Signal:输入信号数组 -
siglen:输入信号数组的长度 -
Kernel:输入卷积核数组 -
kernlen:输入卷积核数组的长度 -
convout:输出数组,用于存储卷积结果
返回值:
-
TINY_OK:卷积成功 -
TINY_ERR_DSP_NULL_POINTER:输入参数为NULL
tiny_conv_ex_f32¶
/**
* @name: tiny_conv_ex_f32
* @brief Extended convolution function with padding and mode options
*
* @param Signal The input signal array
* @param siglen The length of the input signal array
* @param Kernel The input kernel array
* @param kernlen The length of the input kernel array
* @param convout The output array for the convolution result
* @param padding_mode Padding mode (zero, symmetric, periodic)
* @param conv_mode Convolution mode (full, head, center, tail)
*
* @return tiny_error_t
*/
tiny_error_t tiny_conv_ex_f32(const float *Signal, const int siglen,
const float *Kernel, const int kernlen,
float *convout,
tiny_padding_mode_t padding_mode,
tiny_conv_mode_t conv_mode)
{
if (NULL == Signal || NULL == Kernel || NULL == convout)
{
return TINY_ERR_DSP_NULL_POINTER;
}
if (siglen <= 0 || kernlen <= 0)
{
return TINY_ERR_DSP_INVALID_PARAM;
}
if (siglen < kernlen)
{
return TINY_ERR_DSP_INVALID_PARAM;
}
#if MCU_PLATFORM_SELECTED == MCU_PLATFORM_ESP32
if (padding_mode == TINY_PADDING_ZERO && conv_mode == TINY_CONV_FULL)
{
dsps_conv_f32(Signal, siglen, Kernel, kernlen, convout);
return TINY_OK;
}
#endif
int pad_len = kernlen - 1;
int padded_len = siglen + 2 * pad_len;
float *padded_signal = (float *)calloc(padded_len, sizeof(float));
if (padded_signal == NULL)
{
return TINY_ERR_DSP_MEMORY_ALLOC;
}
// Fill padded signal
switch (padding_mode)
{
case TINY_PADDING_ZERO:
// Middle copy only, left and right are zeros (calloc already zeroed)
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen);
break;
case TINY_PADDING_SYMMETRIC:
for (int i = 0; i < pad_len; i++)
{
padded_signal[pad_len - 1 - i] = Signal[i]; // Mirror left
padded_signal[pad_len + siglen + i] = Signal[siglen - 1 - i]; // Mirror right
}
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen); // Copy center
break;
case TINY_PADDING_PERIODIC:
for (int i = 0; i < pad_len; i++)
{
padded_signal[pad_len - 1 - i] = Signal[(siglen - pad_len + i) % siglen]; // Wrap left
padded_signal[pad_len + siglen + i] = Signal[i % siglen]; // Wrap right
}
memcpy(padded_signal + pad_len, Signal, sizeof(float) * siglen); // Copy center
break;
default:
free(padded_signal);
return TINY_ERR_DSP_INVALID_PARAM;
}
// Full convolution
int convlen_full = siglen + kernlen - 1;
for (int n = 0; n < convlen_full; n++)
{
float sum = 0.0f;
for (int k = 0; k < kernlen; k++)
{
sum += padded_signal[n + k] * Kernel[kernlen - 1 - k]; // Convolution is flip+slide
}
convout[n] = sum;
}
free(padded_signal);
// Handle output mode
if (conv_mode == TINY_CONV_FULL)
{
return TINY_OK;
}
else
{
int start_idx = 0;
int out_len = 0;
switch (conv_mode)
{
case TINY_CONV_HEAD:
start_idx = 0;
out_len = kernlen;
break;
case TINY_CONV_CENTER:
start_idx = (kernlen - 1) / 2;
out_len = siglen;
break;
case TINY_CONV_TAIL:
start_idx = siglen - 1;
out_len = kernlen;
break;
default:
return TINY_ERR_DSP_INVALID_MODE;
}
// Copy the selected part to the beginning
for (int i = 0; i < out_len; i++)
{
convout[i] = convout[start_idx + i];
}
}
return TINY_OK;
}
描述:
该函数实现了对输入信号和卷积核的扩展卷积操作,支持不同的填充模式和输出模式。它首先检查输入参数是否为NULL,然后根据平台选择使用ESP32 DSP库或标准C实现进行卷积计算。函数返回卷积结果。
特点:
-
支持ESP32 DSP库加速
-
支持多种填充模式(零填充、对称填充、周期填充)
-
支持多种输出模式(完整卷积、头部卷积、中心卷积、尾部卷积)
参数:
-
Signal:输入信号数组 -
siglen:输入信号数组的长度 -
Kernel:输入卷积核数组 -
kernlen:输入卷积核数组的长度 -
convout:输出数组,用于存储卷积结果 -
padding_mode:填充模式(零填充、对称填充、周期填充) -
conv_mode:卷积模式(完整卷积、头部卷积、中心卷积、尾部卷积)
返回值:
-
TINY_OK:卷积成功 -
TINY_ERR_DSP_NULL_POINTER:输入参数为NULL -
TINY_ERR_DSP_INVALID_PARAM:输入参数无效 -
TINY_ERR_DSP_MEMORY_ALLOC:内存分配失败
函数对比¶
为了帮助读者根据需求选择合适的函数,以下是 tiny_conv_f32 和 tiny_conv_ex_f32 的对比:
| 特性 | tiny_conv_f32 | tiny_conv_ex_f32 |
|---|---|---|
| 填充模式 | 仅零填充(隐式) | 零填充、对称填充或周期填充(显式) |
| 输出模式 | 仅完整卷积 | 完整、头部、中心或尾部模式 |
| 输出长度 | siglen + kernlen - 1 | 根据 conv_mode 可配置 |
| 内存使用 | 无动态分配 | 需要为填充信号动态分配内存 |
| 性能 | 优化(ESP32 支持硬件加速) | 仅在 ESP32 上使用零填充+完整模式时优化 |
| 使用场景 | 简单的零填充完整卷积 | 需要自定义填充和输出模式的高级卷积 |
何时使用 tiny_conv_f32¶
在以下情况下使用 tiny_conv_f32:
-
需要简单的完整卷积结果
-
零填充处理边界是可接受的
-
需要最佳性能(特别是在支持硬件加速的 ESP32 上)
-
希望避免动态内存分配
-
输出长度
siglen + kernlen - 1是可接受的
示例场景:
-
基本信号滤波
-
简单的相关运算
-
需要避免内存分配的实时处理
何时使用 tiny_conv_ex_f32¶
在以下情况下使用 tiny_conv_ex_f32:
-
需要不同的填充策略(对称或周期填充)来处理信号边界
-
需要提取卷积结果的特定部分(头部、中心或尾部)
-
需要输出长度等于输入信号长度(中心模式)
-
处理的信号边界效应很重要(例如图像处理、周期信号)
-
可以接受动态内存分配
示例场景:
-
使用对称填充进行图像滤波以减少边界伪影
-
使用周期填充处理周期信号
-
当输出长度需要匹配输入时,仅提取有效卷积区域(中心模式)
-
边界处理至关重要的高级信号处理